Disclaimer: I’m not a statistician, and no, correlation does not mean causation. Also, I’m not a seismologist. And none of the followings are necessarily true. I’m just stretching my thoughts here!
To begin, read this and then take a look at this. Then come back and we’ll talk about something related.
Welcome back! OK, I don’t really want to talk about causality, I’m interested in the direction of the information flow. What do I mean by that? Let’s say there was an earthquake and two recordings of it are available from two different stations. Can we figure out which one is closer to the centre of the earthquake? Considering both stations use the same devices and the same settings, it should be the one that shows the signals first. Or, at least that’s my guess. Here is a very fake picture:
You’d guess the information is flowing from the station which made the top recording towards the one that made the bottom one. But in general, the signals are not gonna be this clear. So, let me try with another example:

One traditional way of detecting what we could detect with our eyes in the previous picture is to lag the second signal by 

This detects the delay almost exactly where it is. And note that the correlation is positive here. Another way of comparing two signals is to compute their mutual information. If I do the same lagging and replace the correlation with mutual information I’ll get a picture like this:

And here also we can detect the delay with the same precision. There are some considerations that one needs to take into account. One is that the mutual information is less robust than correlation. Another thing is the calculation is much slower for hundreds of lagged signals. Also, one needs to bin the data to find their joint entropy before being able to compute the mutual information, and deciding about how to bin the data could become a problem on its own.
One more detail here is that this delay detection can be done when one of the signals are anti-correlated with the other one. For example, if I turn the second signal above upside down, then do the same analysis, I’ll find out the maximum happens the same way for the mutual information, but at the negatives for cross-correlation, since I’m finding the maximum of absolute values of them.

All that said, there are more established ways of looking at such data out there, and here are a few of them that for any practical purposes, you might wanna use those. The code to compute above examples and mutual entropy is on my GitHub.
Here I want to talk a little about the mutual information itself and how to compute it, along with details about joint entropy.
Entropy and joint entropy
Entropy of a probability distribution 

Now, let’s assume I have a vector 

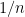


for any probability distribution of
That is, this doesn’t tell me anything about my signal. All of the entries of my signal are probably distinct. Hence, I need to bin my data in order to get a nontrivial probability distribution. Let’s say for the moment I decide to have 10 bins 
nbins and then
edgex = min(X):(max(X)-min(X))/nbins:max(X)+(max(X)-min(X))/nbins; % creat bins edgey = min(Y):(max(Y)-min(Y))/nbins:max(Y)+(max(Y)-min(Y))/nbins; % creat bins Xb = discretize(X,edgex); % bin X Yb = discretize(Y,edgey); % bin Y
Here I’m adding an extra bin at the end to ensure the numbers in the top bin are accounted for. Then I can find the number of unique elements in Xb and Yb by looking at the third output of theunique() command and count how many of each unique number is there by the help of accumarray(), and its probability is the frequency divided by the number of unique numbers. The rest is plugging this information into the formula.
The joint entropy, then is to find the joint probability distribution of Xb and Yb, and then repeating the process. Here the joint probability distribution is computed by counting how many times each ordered pair has appeared in the list. for example if
Xb = [1, 1, 1, -1, -1, -1] and
Yb = [1, -1, 1, -1, 1, -1], then the ordered pair (1,1) appears exactly twice, in the first and third position. To make this example complete, the joint frequency distribution will look like this:
2 1
1 2
and then the joint probability distribution is that devided by 6 = 2+1+1+2 = length(Xb). The joint entropy is then

For eample, in the case of example above, it is

The joint entropy then has the property that

And finally, the mutual information is defined as

Then it is easy to see that the mutual information is always positive, and theoretically no less than 
In the example above, the entropy of both X and Y here is 1, and their joint entropy is about 1.92, which leads to a mutual information of about 0.08. Their entropy tells me that optimally I need 1 bit to express each of them, and their joint entropy says optimally I’ll need less than 2 bits to be able to express both of them(?). But I’m not sure how does this exactly work! That is overall, about 0.08 of their information is overlapping and can be saved in communication.
I am interested in figuring out what is the maximum possible joint entropy and what pair or probability distributions yield it. Same thing for the mutual information. Also, when two signals have zero mutual information, or maximum mutual information, what does it say about them? What does it even mean? Share your thoughts 🙂
—
Most of my understanding of the topic came from this great post.
Many of the details I’ve learned through discussions with Aiden Huffman and Gabi Zeller.
